
Neste primeiro artigo da série, exploramos os fundamentos de Data Quality e seu papel estrutural em iniciativas de Master Data Management (MDM).
Dados mestres confiáveis não surgem por acaso
Empresas investem continuamente em analytics, automação e IA. Porém, muitas iniciativas falham por um motivo simples: baixa qualidade dos dados mestres.
Cadastros duplicados, campos incompletos e divergências entre sistemas geram impactos diretos em Processos operacionais, Integrações, Indicadores, Experiência do cliente, dentre outros.
Em ambientes corporativos complexos, problemas em dados mestres raramente ficam isolados. Um erro em cadastro de cliente, fornecedor ou material normalmente se propaga entre múltiplos sistemas.
Por isso, em ambientes orientados por integração, automação e IA, confiabilidade dos dados mestres deixou de ser diferencial técnico e passou a ser requisito operacional.
O papel do Data Quality em MDM
O principal objetivo de um MDM é garantir que entidades críticas da organização — como clientes, fornecedores, materiais e ativos — sejam gerenciadas de forma consistente, padronizada e confiável ao longo de toda a operação e de todo seu ciclo de vida.
Nesse contexto, Data Quality não atua como uma iniciativa paralela ao MDM, ela é uma das disciplinas estruturais do próprio processo de gestão de dados mestres.
Na prática, o MDM estabelece os processos e controles para gerenciamento dos dados mestres, enquanto o Data Quality garante que esses dados permaneçam confiáveis para uso operacional e analítico.
DAMA DMBOK: qualidade como disciplina contínua
O DAMA DMBOK define Data Quality como a capacidade do dado atender corretamente ao uso esperado.
Essa definição é importante porque desloca o foco da simples “correção de erros”.
No DMBOK, Data Quality envolve:
- Padronização
- Governança
- Monitoramento contínuo
- Regras de negócio
- Controle operacional
- Gestão de causas-raiz
O framework reforça que Data Quality é uma disciplina contínua de governança, e não apenas em uma atividade corretiva executada pontualmente.
ISO 8000: padronização e interoperabilidade
A ISO 8000 complementa essa visão com foco em padronização e troca consistente de informações.
A norma enfatiza temas como:
- Precisão semântica
- Estrutura padronizada
- Identificação única
- Rastreabilidade
- Interoperabilidade entre sistemas
Na prática, a ISO 8000 ajuda a responder uma pergunta importante: “O dado consegue ser entendido da mesma forma em diferentes sistemas e processos?” – Esse problema é comum em ambientes com múltiplos ERPs, integrações e aplicações distribuídas.
As dimensões do Data Quality
Data Quality não é medido por um único critério. A avaliação depende de múltiplas dimensões como:
- Completude – Todos os atributos obrigatórios estão preenchidos?
- Consistência – Os dados permanecem coerentes entre sistemas?
- Unicidade – Existe apenas um registro válido para cada entidade?
- Precisão – O dado representa corretamente a realidade?
- Atualidade – O dado continua válido para o contexto atual?
- Conformidade (Validade) – O dado segue padrões internos e exigências regulatórias?
Nem toda dimensão possui o mesmo peso
Em iniciativas maduras de Data Quality, nem todas as regras possuem o mesmo impacto operacional.
Um erro na máscara de um telefone não possui a mesma criticidade de um erro em dados fiscais ou bancários.
Por isso, modelos de qualidade normalmente utilizam dois conceitos fundamentais em complemento às dimensões – são eles:
- Severidade
- Score de Qualidade
Severidade: o impacto da regra no negócio
Cada regra de qualidade recebe um nível de severidade baseado no impacto operacional do dado.
O modelo mais comum utiliza três níveis:
| Severidade | Peso | Impacto |
| Alta (H) | 3 | Impacta processos críticos, compliance ou faturamento |
| Média (M) | 2 | Impacta operação, mas possui contorno operacional |
| Baixa (L) | 1 | Impacto limitado ou informacional |
Na prática:
- Um fornecedor sem dados bancários pode ser classificado como Alta severidade
- Um material sem texto longo complementar pode ser classificado como Média severidade
- A ausência de telefone secundário em um cliente pode ser classificado como Baixa severidade
Esse modelo evita um erro comum em projetos de qualidade: tratar todos os problemas de qualidade de dados como equivalentes
Score de Qualidade: priorização baseada em impacto
O Score de Qualidade representa o percentual de conformidade considerando o peso das regras aplicadas.
Nesse modelo, regras mais críticas possuem maior influência no resultado final.
A lógica normalmente funciona assim:
- Regras válidas contribuem para o score
- Alertas e falhas reduzem o resultado
- Regras críticas penalizam mais fortemente o objeto avaliado
Exemplo simplificado:
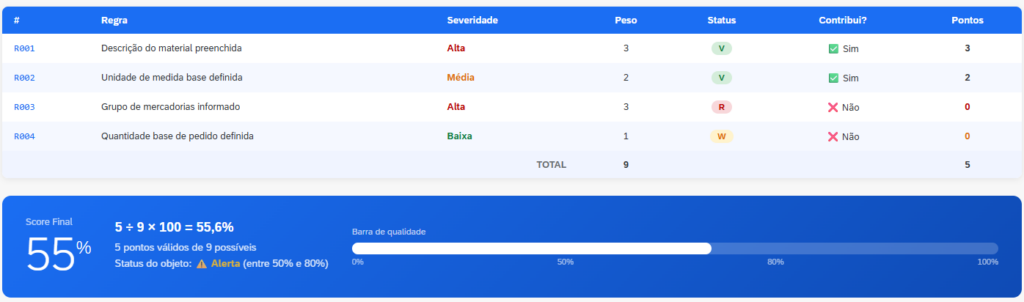
Mesmo com duas regras válidas, a falha em uma regra crítica (severidade alta) reduz significativamente o score final.
Score de Qualidade precisa refletir risco operacional
Esse modelo permite que o Data Quality seja tratado de forma mais estratégica.
Ao invés de apenas contar erros, a organização passa a medir:
- Impacto operacional
- Risco regulatório
- Criticidade do processo
- Prioridade de correção
Na prática, isso torna o monitoramento muito mais eficiente.
Problemas críticos deixam de ficar “escondidos” dentro de métricas genéricas de completude ou conformidade.
Data Quality não é apenas conformidade técnica
Quando severidade e score são aplicados corretamente, o indicador de qualidade deixa de representar apenas “quantidade de erros”. Ele passa a representar risco real para o negócio.
Esse é um dos pontos mais importantes em ambientes de Dados Mestres: Em MDM, qualidade não é apenas medir quantidade de erros — é priorizar aquilo que realmente impacta operação, compliance e negócio.
Data Quality não é saneamento pontual
Muitas empresas ainda tratam qualidade como um projeto temporário de limpeza de dados onde o foco normalmente fica em Remover duplicidades, completar atributos vazios, etc.
O problema é que os erros retornam rapidamente. Sem governança, o processo continua produzindo dados inconsistentes.
Por isso, Data Quality precisa atuar de forma contínua através de:
- Regras preventivas
- Monitoramento
- Gestão de exceções
- Ownership e Stewardship
- Indicadores de qualidade
Qualidade sustentável é construída através de governança, monitoramento e prevenção contínua — não apenas por iniciativas pontuais de correção.
Conclusão
Explorar esse tema reforça que, em ambientes cada vez mais orientados por IA e automação, a qualidade dos dados mestres deixa de ser apenas uma preocupação operacional e passa a ser um requisito para confiabilidade dos processos e decisões.
No próximo artigo, vamos explorar como esses conceitos são aplicados na prática em iniciativas de Dados Mestres, incluindo monitoramento contínuo, tratamento de duplicidades, correções automáticas via regras e gestão da qualidade dos dados.
Fique de olho!